# HTTP缓存
通过复用以前获取的资源,可以显著提高网站和应用程序的性能。Web 缓存减少了等待时间和网络流量,因此减少了显示资源表示形式所需的时间。通过使用 HTTP缓存,变得更加响应性。
缓存的种类有很多种, 我们主要需要了解浏览器私有缓存。
虽然 HTTP 缓存不是必须的,但重用缓存的资源通常是必要的。然而常见的 HTTP 缓存只能存储 GET 响应,对于其他类型的响应则无能为力。缓存的关键主要包括request method和目标URI(一般只有GET请求才会被缓存)
# 缓存控制流程
先看一个图
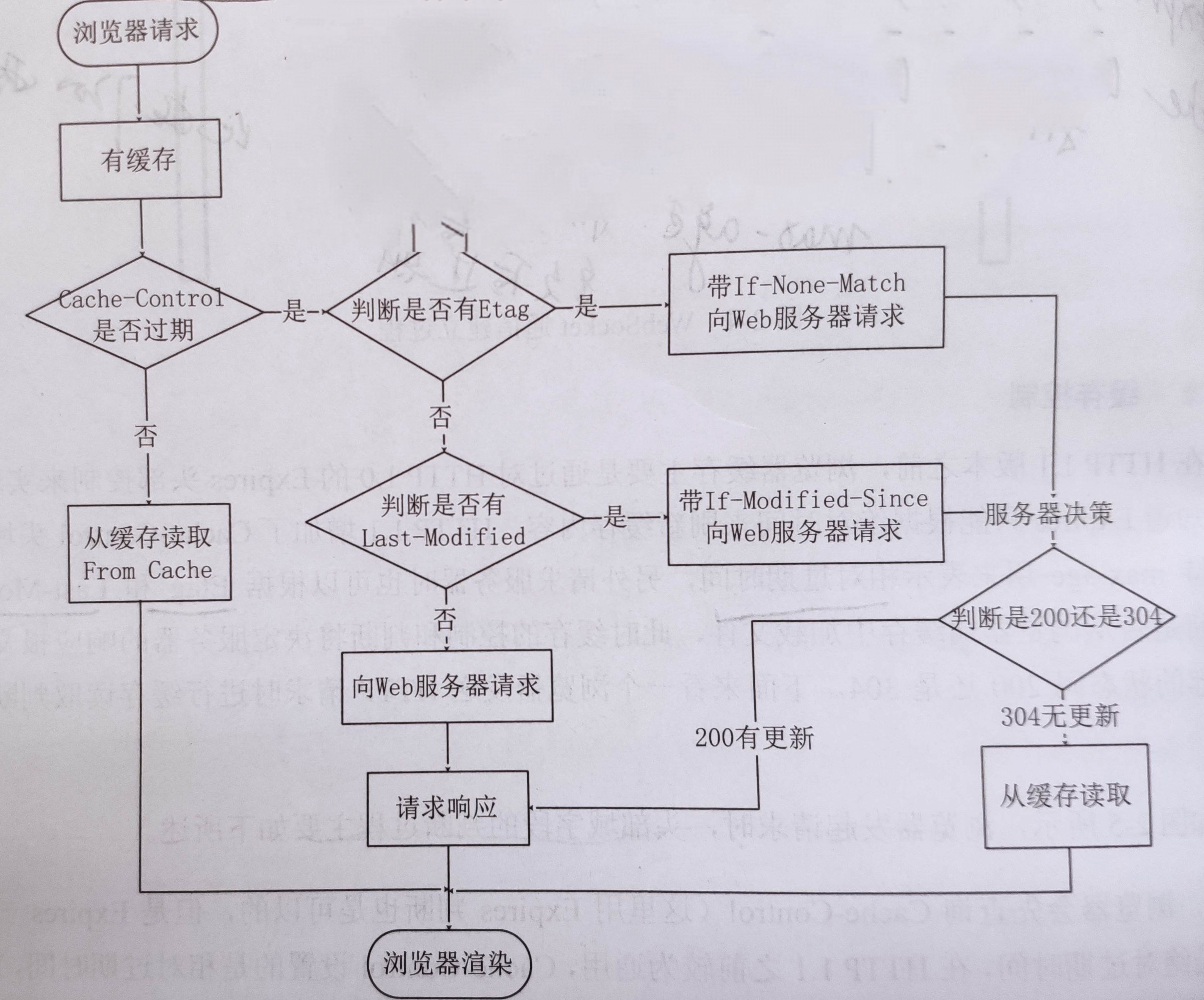
HTTP1.0主要通过Expires 头部实现。Expires 存储了内容的绝对过期时间。
WARNING
expires 有一个缺陷,即要求服务端和客户端时间同步,如果不同步,假如服务器慢了,传给客户端的时间可能一直过期了。
HTTP1.1新增了Cache-Control头部, 可以根据max-age表示相对过期时间, 另外服务器也可以根据Etag和Last-modified来判断是否从浏览器端加载文件, 此时缓存的控制将决定服务器的响应报文中头部的状态码是200还是304.
缓存判断过程
- Cache-Control或者Expires是否过期,没有过期, 直接从缓存读取, from disk cache(from memory cache) 这种http code是200, 属于强缓存
- 后面的Etag和Last-Modified属于协商缓存, 顾名思义就是和服务端协商过后的结果。 Etag 一般是根据文件内容生成的一串字符串
- 如果过期了, 判断是否有Etag响应头, 有的话带上If-None-Match请求头, 值是ETag的值,服务器判断是200还是304, 如果返回304则从缓存读取
- 如果没有ETag, 那就判断是否有Last-Modified, 有的话带上If-Modified-Since头部, 服务器判断是200还是304
304的响应头也可以同时更新缓存文档的过期时间
# Cache-Control
no-store缓存中不得存储任何关于客户端请求和服务端响应的内容。每次由客户端发起的请求都会下载完整的响应内容。no-cache不实用本地缓存,每次都走协商缓存public private"public" 指令表示该响应可以被任何中间人(比如中间代理、CDN等)缓存。若指定了"public",则一些通常不被中间人缓存的页面(因为默认是private)(比如 带有HTTP验证信息(帐号密码)的页面 或 某些特定状态码的页面),将会被其缓存。
而 "private" 则表示该响应是专用于某单个用户的,中间人不能缓存此响应,该响应只能应用于浏览器私有缓存中。
max-ageCache-Control: max-age=31536000过期机制中,最重要的指令是 "
max-age=<seconds>",表示资源能够被缓存(保持新鲜)的最大时间,max-age是距离请求发起的时间的秒数
# ETags
ETag HTTP响应头是资源的特定版本的标识符。作为缓存的一种强校验器,ETag响应头是一个对用户代理(User Agent, 下面简称UA)不透明的值。对于像浏览器这样的HTTP UA,不知道ETag代表什么,不能预测它的值是多少。如果资源请求的响应头里含有ETag, 客户端可以在后续的请求的头中带上If-None-Match头来验证缓存。
# Last-Modified
Last-Modified 响应头可以作为一种弱校验器。说它弱是因为它只能精确到一秒。如果响应头里含有这个信息,客户端可以在后续的请求中带上 If-Modified-Since 来验证缓存。
# Vary 响应
Vary HTTP 响应头决定了对于后续的请求头,如何判断是请求一个新的资源还是使用缓存的文件。
当缓存服务器收到一个请求,只有当前的请求和原始(缓存)的请求头跟缓存的响应头里的Vary都匹配,才能使用缓存的响应。
使用vary头有利于内容服务的动态多样性。例如,使用Vary: User-Agent头,缓存服务器需要通过UA判断是否使用缓存的页面。如果需要区分移动端和桌面端的展示内容,利用这种方式就能避免在不同的终端展示错误的布局
DANGER
对于面试来说, 能清楚的说出缓存控制的流程很有必要, 同时在实际的工作中,必然也会遇到关于缓存的问题, 那么如何发现并且解决这些问题,通过这篇知识点可能也就有了大致的方向,我想这是我们学习的一个原因。
# 关于设定缓存
我们可以使用各种服务端语言的各种 setheader、appendHeaders等函数来添加请求头, 或者通过nginx代理也可以设定响应头。
或者也可以直接利用 <meta>设定缓存
<meta http-equiv="Cache-Control" content="no-cache, no-store, must-revalidate">
<meta http-equiv="Pragma" content="no-cache">
<meta http-equiv="Expires" content="0">
# HTML meta tags vs HTTP response headers
Important to know is that when an HTML page is served over an HTTP connection, and a header is present in both the HTTP response headers and the HTML <meta http-equiv> tags, then the one specified in the HTTP response header will get precedence over the HTML meta tag. The HTML meta tag will only be used when the page is viewed from a local disk file system via a file:// URL. See also W3 HTML spec chapter 5.2.2 (opens new window). Take care with this when you don't specify them programmatically because the webserver can namely include some default values.
Generally, you'd better just not specify the HTML meta tags to avoid confusion by starters and rely on hard HTTP response headers. Moreover, specifically those <meta http-equiv> tags are invalid (opens new window) in HTML5. Only the http-equiv values listed in HTML5 specification (opens new window) are allowed.
一个网页如果基于HTTP连接加载,同时由服务器和<meta>标签设定请求头, 服务端的优先级更高。<meta>标签设定的请求头只有在本地打开(比如file://形式)才是有效的。一般来说不用指定 HTML 元标记以避免初学者混淆并依赖硬 HTTP 响应标头。此外,特别是那些 <meta http-equiv> 标签在 HTML5 中是不可用的。仅允许 HTML5 规范 (opens new window) 中列出的 http-equiv 值。
← 关于HTTPS HTTP Cookie →